In January 2014 I started a formidable project: I am writing sheet music editing software. I feel I am very qualified to do so because I am a musician, a composer who knows a lot about music notation, a good software developer, I always put myself in the user’s shoes and I have been using music software for 24 years, having accumulated a little list of wishes that have never been granted by Finale, Encore, Overture, Sibelius, Notion etc.
In fact, the project grew out of my dissatisfaction with all these existing programs. As a composer, I feel using their software is frequently uncomfortable. Even Sibelius, the most user-friendly of them all. Maybe the result of my efforts will be a little more comfortable to use.
Each of these programs has their own set of problems...
All these programs were written in C++. I am creating mine in the Python language, such that the result will be hackable by its users. They will be more able to scratch their itches.
But the problem is that the scope of the project is so daunting. I have a huge backlog of features I need to implement before my solution can compete. I estimate the entire project will take 2 man-years before it can be useful to anyone. It is July already and I have been able to work on this project for only 2 man-months, so there are 22 to go. When I think about this, I feel I am a little crazy for even having started it. If I give up, I will have wasted X months of my life and nobody will ever have had any use for any of it.
After 2 man-months of work, what do I have? My program reads scores created in other programs in the MusicXML interchange format and puts the score in memory. (Representing music in the computer memory poses intimidating problems by itself.) It also shows a subset of the music symbols on the screen. You can zoom in and out, you can cycle through a few color themes and you can change the title of the piece. Undo and redo have been implemented and there’s a neat framework that will be used for every user command. Many keyboard shortcuts have been planned and placed in a configuration file so the user can change any of them if she wishes to. A music cursor already exists that travels through all notes in the piece. But you still cannot add, change or delete a single note. And there is so much still not shown on the screen... There are no beams, no slurs, no articulations, no dynamic markings etc.
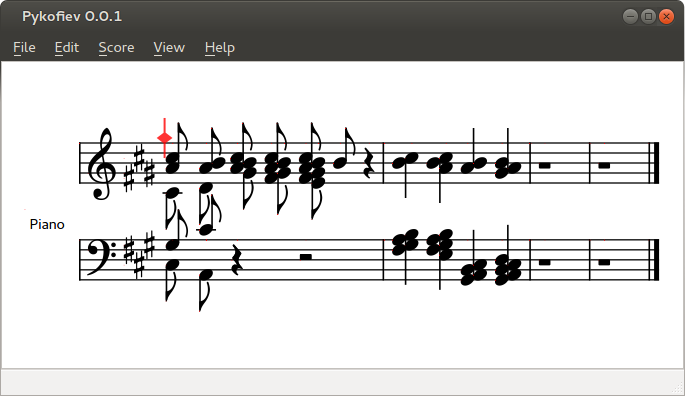
Screenshot of an alpha version of my music editor showing a test of clusters
This is because music notation is very complex. Simply displaying it on screen is very hard. If you are a musician, can you articulate the rules to display clusters of notes? Questions of spacing have to be faced... In my software, from day zero, the collisions (between music signs) that plagued this kind of software for years and years, making users drag symbols all the time... these placement problems are considered bugs with the greatest priority. Nobody wants to be fixing these manually, the program must get this right without any human help!
If this project is so hard even today, I can imagine what the Finale developers accomplished back in 1988 ― such software did not yet exist. Respect goes out to them, deep respect. Today I have open music fonts that I can use, the Python language and the Qt framework which do so much of the work for me, especially concerning graphics. Even creating PDF files probably won’t be much different than showing the stuff on the screen, thanks to Qt.
Obviously I should not be doing this alone. This post is a sort of call for help, as there are some kinds of help I could use:
I have dreamed of writing this software for decades. In my dreams it would always be open source. But right now I don’t see how open source could ever repay such an effort. I need to be adequately compensated for this work. This will probably be cheap software, but not (immediately) open source ― even though I like free software so much.
Can you help? Any messages about the project are very welcome!
Here is my opinion on Python web frameworks.
Pyramid is currently the best choice because:
The only drawbacks of Pyramid might be:
Let’s compare this to Django. The advantages of using Django today might be:
The disadvantages of Django are:
Advantages of Flask:
Disadvantages of Flask:
What advantages do I see in Google App Engine?
Disadvantages?
What advantages do I see in web2py?
Disadvantages?
If you are setting out to write a large application in Python using a relational database, this long post is for you. Herein I share some experience acquired over 6 months while writing large applications that use SQLAlchemy (the most advanced ORM available for the Python language) in a large team.
To be honest, I think this post might be too convoluted, trying to teach too many things at once. But it is really trying to show how multiple aspects converge to fail together.
It would be near impossible to explain all the reasons for the bad software I have seen, but it is safe to say they result from the interplay of some forces:
I will talk about all of these forces, their relationships and some solutions.
Unless the software is to be extremely short-lived, it never pays off to write it in a hurry. Creating software takes time, research, learning, experimentation, refactoring and testing. Every concession you make to haste will have nasty repercussions for sure. But don’t believe me; suffer these yourself ― everyone does.
The recommendations contained in this section stand as of April 2014.
When writing large applications, one should choose tools more carefully. Don’t just go the quickest path. For instance, it pays off to choose a more complex web framework such as the full-featured, beautifully designed and thoroughly documented Pyramid, which shows a better defined scope and superior decoupling, than something like Flask, which gets small jobs done more quickly, but suffers from thread local variables everywhere, incomplete documentation that seems to only explain something to someone who already knows it, and plugin greed (Flask enthusiasts may want everything in the system to be a Flask plugin).
You will be tempted to choose Django. Its single advantage is its community size. But it suffers from age and the need for backwards compatibility. Django had to create its own ORM (SQLAlchemy didn’t exist then) which is much worse than SQLAlchemy. Also, if you only know Django, you are likely to have a misconception of the importance of SQLAlchemy. You see, the Django ORM follows the Active Record pattern, while SQLAlchemy adheres to the completely different Unit of Work pattern. It might take you some time to understand the session and the lack of a save() method on your models. This talk helps with that. Finally, Django’s templating engine is severely (and deliberately) handicapped; Genshi, for instance, is much, much richer in features.
Django is also monolithic (as in Not Invented Here syndrome) ― a design trait that flies in the face of everything I say below ― and you see people boasting that Django is a single package, as if this were a good thing. Often they avoid using the package management tools in Python and that is just silly. Many things in Django are just silly...
Now, SQLAlchemy is so advanced in comparison to all the other ORMs in the Python world that it is safe to say, if you are accessing a relational database through anything else, you are missing out. This is why you should not choose the web2py web framework, either. It does not have an ORM, just a simple DAL to generate SQL.
(Since I have already recommended Pyramid and SQLAlchemy, why not a word about form validation toolkits? Since the ancient FormEncode, many libraries have been created for this purpose, such as WTForms and ToscaWidgets. I will just say that you owe it to yourself to try out the Deform and Colander combination – they have unique features, such as the conversion of data to a Python structure, and the separation of schema (Colander) from widgets (Deform), that really get it right. This architectural clarity results in a much more powerful package than the competition. But again, it will be necessary to spend a little more time learning how to use these tools. The learning curve of the competition might be less steep, but you can suffer more later on.)
You probably know the MVC (model, view, controller) architecture as applied to web development. (If you don’t, you are not ready to create a large application yet: go make a small one first, using an MVC framework, and come back to this post in a few months. Or years.)
Strictly speaking, MVC is an ancient concept, from early Smalltalk days, that doesn’t really apply to web development. The Django folks have correctly understood that in Python we actually practise MTV (model, template, view):
But wait. Where? In the view or in the model? Where should you put the soul of your project: the business rules? The template layer is automatically out because it is not written in Python. So 3 possible answers remain:
MTV certainly is all you need to create a blog. But for more complex projects, there is at least one layer missing there. I mean, you need to remove the business logic from where it stands and put it in a new, reusable layer, which most people call a “Service” layer, but I like to call “Action” layer.
Why do you need that?
In larger applications, it is common for a single user action to cause multiple activities. Suppose, for instance, the user successfully signs up for your service. Your business rules might want to trigger many processes as a consequence:
This is a good example of what we understand by a “business rule”: Given a user action (e. g. sign up), these are the activities the system must perform. This business rule had better be captured in a single function; in which layer should this function go?
If all this were implemented in a model, can you imagine how complex it would be? Models are hard enough when they focus only on persistence. Now imagine a model doing all that stuff, too. How many external services does it have to consume? How many imports are there at the top of the file? Don’t some of those modules, in turn, want to import this model, too, creating a cyclic dependency that crashes the system before it starts?
A circular dependency alone is a clear sign that you aren’t seeing your architecture properly.
It simply isn’t clean for a model to depend on Celery, to know how to send emails and SMS and consume external services etc. Persistence is a complex enough subject for the model to handle. You need to capture many of these business rules outside of the model – in a layer that stands between the model and the view. So let’s call it the “Action” layer.
Also remember that a model usually maps to a single table in the relational database. If you are at once inserting a User and a Subscription, which of these 2 models should contain the above logic? It is almost impossible to decide. This is because the set of activities being performed is much larger than either the User’s concerns or the Subscription’s concerns. Therefore, this business rule should be defined outside of either model.
When a dev is performing maintenance, sometimes she wants to run each of these steps manually; other times she will execute the whole action. It helps her to have these activities implemented separately and called from a single Action function.
You might wonder if what I am proposing isn’t really an instance of an antipattern called Anemic Domain Model. Models without behaviour are just contrary to object-oriented design! I am not saying “remove all methods from your models”, but I am saying “move away methods that need external services”. A method that finds in a model all the data that it needs... really wants to belong to that model. A method that looks out to the world, consumes external services and barely looks into self... has been misplaced in the model.
Another reason that makes this a successful architecture is testing. TDD teaches a programmer to keep things decoupled and it always results in better software. If you have to set up a Celery application and who knows what other external services before you can test your model, you are going to be frequently in pain.
There is a final reason to keep business rules outside the view layer. In the future, when you finally decide it’s time to switch from Flask to Pyramid, you will be glad that your views are as thin as possible. If all your view does is deal with the web framework and call a couple methods on your Action layer, it is doing one job (as should be) and code is properly isolated. Web frameworks can be greedy; don’t let them have their way with your system.
So here are the layers I propose for a typical large application in Python:
This architecture helps avoid heroic debugging sessions insofar as it clearly defines responsibilities. It is also eminently testable because it is more decoupled, thus requiring less test setup and fewer test mocks and stubs.
Good architecture is all about decoupling things. If you ever catch yourself trying to resolve a cyclic dependency, rest assured you haven’t thought well about the responsibilities of your layers. When you see yourself giving up and importing something inside a function, know that your architecture has failed.
It also goes without saying that your web app should be kept separate from your Celery (tasks) app. There can be code reuse between them ― especially models ― but there is no reason for a Celery app to ever import the web framework! Obtaining configuration is no exception. Reading configuration is easy in Python.
Python is a very flexible, expressive, reflexive language. A down side of its dynamism is that it catches fewer errors at “compile time”. One wouldn’t create large systems in Java without automated testing today; even less so in Python.
You start writing tests as soon as you realize their importance towards your confidence in the software. You understand this and you start writing them. The first tests you write have enormous value. They give you an incredible boost in confidence in your system. You are having fun.
However, soon your tests start feeling more like a burden. You now have hundreds of tests and the test suite takes forever to run ― minutes, even. In this sense, each new test you write makes your life worse. At this point, some might become disenchanted and conclude testing isn’t worth it. A premature conclusion.
You thought you knew how to write tests. But in your naiveté, you have been writing all integration tests. You call them unit tests, but they really aren’t. Each test goes through almost the whole stack in your system. You put your mocks at the most remote points possible. You thought this was good (it was testing more this way). Now you start to see this isn’t good.
A unit test is the opposite. A real unit test is focused like a laser. It executes only one function of one layer, it uses mocks to prevent descent into other layers, it never accesses external resources, it asserts only one condition, and it is lightning fast.
To add insult to injury, when your tests do their job ― showing you that you messed up ― they are a nuisance. Instead of a single focused failed unit test showing you exactly where you did something wrong, you have dozens of integration tests failing (all of them for the same reason, because they all go through the same code) but it takes you a long time to figure out where the bug really is. You still need some heroic debugging. You need to learn to write better tests!
Experts recommend you write 99% of real, focused, mocked, sniper, unit tests. And only 1% of all-layers-encompassing integration tests. If you had done so from the start, your unit test suite would still be running in only a couple seconds, which is required for TDD to be feasible. If a unit test is not instantaneous (less than 10 milliseconds for sure), it’s really some other kind of test, but not a unit test.
If this were a small application, you could still get away with your sluggish integration tests. But we are talking about large applications, remember? In this context, the reality is, you either optimize your tests performance, or you cannot practise TDD!
Also, as you can remember, some tests have been difficult to write. They required too much work to set up. (Integration tests tend to.) Someone explains this is because your tests aren’t really unit tests and you aren’t doing Test First – you are writing tests to existing code that wasn’t written with sufficient decoupling that it would be easily testable. Here you start to see how TDD really changes not only the tests, but your actual system, for the better.
Watch these talks about test writing.
To find out which are your 2 slowest tests, run this command:
py.test -s --tb=native -x --durations 2
But the system uses SQLAlchemy! Data travels between layers in the form of model instances. A database query is performed and boom, you are already over the 10ms limit. This forces you to conclude: if it hits the database, it is not a unit test. (It is instantaneous to instantiate a SQLAlchemy model, but it is expensive to talk to SQLite, even if it is in memory.) Yeah, TDD will force you to keep queries, session.flush() and session.commit() outside of a function suitable for unit testing!
You still need to write a few integration tests anyway. They test the contracts between the layers and catch bugs that unit tests don’t catch. For integration tests, John Anderson has a good approach: Use SQLAlchemy, but never allow the transaction to be committed. At the end of each test, do a session.rollback() so the next test can run without the database having been changed. This way you don’t need to recreate tables for each test you run.
To make that possible, you can’t be committing the session all over the place. It is probably best to stipulate a rule: the system can only call session.commit() in the outermost layer possible. This means the web view or the Celery task. Don’t commit in the Model layer! Don’t commit in the Action layer!
This creates a final problem: How do I write a unit test for a task, if the task commits the transaction? I need a way for the test to call the task saying: exceptionally, just this once (because this is a test), please don’t commit. Otherwise the unit test would hit the database server and exceed the maximum of 10 milliseconds.
I finally came up with a mechanism to give an external function (e. g. a test case) control over whether the transaction is to be committed or not. With this scheme, a task commits the transaction by default, but allows a test to tell it not to commit. You are welcome to the following code:
from functools import wraps
def transaction(fn):
'''Decorator that encloses the decorated function in a DB transaction.
The decorated function does not need to session.commit(). Usage::
@transaction
def my_function(): # (...)
If any exception is raised from this function, the session is rewinded.
But if you pass ``persist=None`` when calling your decorated function,
the session is neither committed nor rewinded. This is great for tests
because you are still in the transaction when asserting the result.
If you pass ``persist=False``, the session is always rewinded.
The default is ``persist=True``, meaning yes, commit the transaction.
'''
@wraps(fn)
def wrapper(*a, **kw):
persist = kw.pop('persist', True)
try:
fn(*a, **kw)
except:
db.session.rollback()
raise
else:
if persist is False:
db.session.rollback()
elif persist is True:
db.session.commit()
return wrapper
This post is dedicated to my friend Luiz Honda who taught me most of it all.
― Acho que hoje ele não vem. Já está tarde ― disse vovô, esperançoso.
Olhei para trás: os olhinhos castanhos de meu priminho Vit ostentavam sua diversão. Como gostávamos de brincar de espião! Fiz sinal de silêncio com a maior veemência.
― Ele sempre vem no início do mês. Pode tardar, mas não tem misericórdia ― soluçou vovó.
― Arre, mulher! É por isso que nada de bom acontece nesta casa! ― bufou vovô roucamente.
Estiquei a cabeça para além da quina do armário. Suas feições graves não me encontraram.
Titia surgiu do quintal limpando as mãos. Escondi-me de novo. ― Mas ela tem razão ― contemporizou. ― Ficando aqui, estamos sujeitos a essa desgraça!
― O que não tem remédio... ― grunhiu vovô, aproximando-se. ― Isso não tem remédio!
Disparamos na direção da entrada da casa com estardalhaço. Vit continuou brincando como se não tivesse escutado nada. Eu era maior e não sei se entendia mais, mas a conversa me deixara um pouco preocupado.
― Crianças, não saiam! ― gritou vovó, lá da cozinha.
Esgueirando-nos pelos cantos, chegamos à janela da frente. Olhamos para fora com cuidado para não sermos detectados, pois restava uma pitada de crepúsculo. Ventava muito: a árvore do outro lado da rua parecia tentar desprender-se do chão. Meus pensamentos foram interrompidos por um estalo medonho, seguido de um trovão, que arregalou os olhinhos do meu primo de susto ― e eu mesmo tive um arrepio, que o raio deve ter caído bem ao lado da casa. Em seguida desabou uma chuva de granizo, a qual assistimos da janela.
Um carro ― lembro que era grande e escuro ― parou em frente à nossa casa. Um minuto depois, desceu uma enorme figura oculta numa capa de chuva bege. Enquanto fechava a porta, pensei ter avistado... o quê? Pelo?
Vit riu baixinho e me puxou para baixo. Empurrei-o ― tinha que olhar ― algo não estava certo.
O vulto dirigiu-se à casa da frente. Segundos depois, abriram e ele entrou.
― É um mon ― começou Vit, mas tapei sua boca, pois nesse momento pude discernir gritos vindo da casa da frente, mesmo sob a chuva. O alarido durou alguns segundos, o que era? Consternação? Pavor? Meu mal-estar só aumentava.
A chuva agora estava mais fraca. A porta se abriu e o vulto veio direto para a nossa casa. A cada passo, um pesado estalido. Vit apertou meu braço com aflição. Arrependi-me de fitá-lo, pois ele detectou o medo nos meus olhos. A campainha soou dura: de um pulo, puxei meu primo para trás da cortina, de onde assistimos o resto da hedionda cena.
Vovô veio da cozinha com um olhar de profundo desgosto. ― Não abra ― instou vovó, mas ele a ignorou e escancarou a porta de uma vez só. E junto com a chuva, aquela voz odiosa entrou na casa:
― O aluguel atrasado, senhores.
If you are into classical music, you know how hard it is to organize your audio files.
The most important problem is lack of support for the “Composer” tag in music player software. For a while, this led me to the idea of reusing the mainstream “artist” tag to contain composer information. But then performer information must go into other tags such as “Album” or “Comment”.
The advantage of this approach is that it works with any and all music players.
But it has many disadvantages. First of all, tagging your music becomes an endless nightmare: no tagging software I have encountered out there does it this way, so basically you would have to make corrections manually. Forever. Remember that your are files always coming from many different sources, so you would have to keep track of which files have already been converted to your system.
Also, this kind of reasoning is just conceptually wrong. Though the idea of the “artist” in music is a wrong concept by itself, what it really means in practice is “performer”. If you start abusing concepts you end up with nightmares as repulsive as this system:
http://musicbrainz.org/doc/ClassicalStyleGuide
No solution could be less correct in data normalization terms...
Finally I found it easier to just use the correct tags. Use the “Composer” tag for the composer. The disadvantage is, you have to work harder to find software that supports it. But it is not impossible. Apple products support the “composer” tag. On a PC (Windows or Linux) one can use powerful music players such as Amarok which fully supports the “composer” tag. (On Ubuntu Linux, you just type sudo apt-get install amarok.)
What about my phone? I’ve been unable to find an Android music player with support for the “composer” field. I did find hints on the web and tried a few players, but the tips were written years ago and apparently the newer versions do not support the “composer” tag anymore.
Since phones are unable to carry that much music anyway, I intend to just use any directory-based player. What’s important is that my collection will be correct and give me less of a headache.
Summing up, I have 2 pieces of advice:
So you are going to watch War Horse, Spielberg’s movie of 2011. Here is what you need to know. (No spoilers here, this is safe to read.)
This is a traditional movie in many ways. But which traditions? Well, you are going to see a (non-satirical) picaresque fictional story about a horse in First World War times, derived from a book for children.
So the foremost tradition is that of the horse movie. You get everything you would expect: themes of friendship between a youngen and a special horse who is one of the most important characters, stunning visuals that only nature and animals can provide, gallops, adventure etc.
Because the horse is perhaps the main character, he is going to suffer. Be prepared for this. However, it’s all in good taste.
Now remember the story has something of a picaresque quality, without really belonging to this genre. To me this means the hero goes through adventures in different places during his life, and whether characters reappear later is anyone’s guess. These episodes may sometimes seem a bit disconnected from each other, however this is part of the wonder, you would exclaim: “what an interesting life”! And I have to say, this falls quite nicely upon a traditional horse movie character who would like his freedom.
So if the plot is sometimes stretched, well, in my opinion this is just part of the genre. There is no satire though.
The First World War is the circumstance that keeps these episodes together. But this is only a war movie to the extent of old, traditional war movies. I mean, this isn’t a remake of Private Ryan, gore isn’t the focus. This isn’t an ultra-realistic movie in any way and Spielberg has been able to mix these 2 genres (war and horse) in a tasteful way.
I guess I mean to say, there is war in the movie, but it isn’t exactly a war movie, it isn’t focused in showing the raw horrors of war, and if it were, you might care that much less about the horse. You gotta like the horse, otherwise the movie won’t make sense! And I understand this is true, that horses did indeed suffer in that war.
The fact that the Germans speak English put some people off; they wanted to see subtitles. I guess they were expecting a contemporary war movie. But remember that children are to be included in this audience... I, for one, felt it refreshing to see raw realism – which would be pointless here anyway – give way to a more direct way to tell the story. This looks back to old war movies, in which foreign characters might speak their own languages a bit for effect, but not when you really had to understand what they were saying. In many ways, that was a better way to just tell a story.
Some people complain that the first part was slow. Another complaint is that there wasn’t enough friendship established between the horse and the boy. I thought the balance was perfect between these two opposing forces.
Finally, you get traditional John Williams music, not so memorable but perfectly adequate. And Spielberg is the perfect director to manipulate your heart, which makes many people mad at him. How dare he?!
Now you are prepared to be entertained by a pretty good film, knowing that it won’t change your life.
When people buy a new computer, it tends to come with Windows preinstalled. Because of this, most people just use it – unaware that it would be much better for them to install Linux instead. Further, Linux is free.
Here is my list of the most important reasons to avoid Windows:
There is a whole industry built on the paranoia, the fear of catching viruses, trojan horses and other exploits. Ask yourself this: How is it possible that the other operating systems (Linux and Mac OS X, as well as others) are much more secure, their users don’t worry, no antivirus software is needed, and things work well with rare exceptions? Antivirus software is constantly slowing down any Windows computer, checking every operation. It is just a very unfortunate thing to worry about...
And they want your money. Antivirus software is always intruding, showing to you that it is working for you, this way you will always remember it is useful, and you are more likely to pay for protection every year.
What is this like on Linux? No worries, no antivirus software is needed.
Because of the antivirus software constantly running in the background, there is no way a Windows system can compete with secure systems in terms of performance.
The user is constantly being bothered by one or another program (Windows itself, Java, antivirus software, web browsers etc. etc.) which wants to be updated. This could easily be so different!
What is this like on Linux? There is a single packaging system to install and update software programs. This means when you are informed of available updates, the information is comprehensive of all the software you have. On Linux you get interrupted much less.
Further, the software that comes with a Linux distribution is much more comprehensive than that which comes with Windows. For instance, on Linux it is very easy to get all the multimedia codecs installed, while on Windows there are many options for this, all of which feel unsafe.
Windows thinks disconnection time is appropriate for installing software updates. (The process continues when the computer starts up again.) There is a way to turn off the computer without installing anything, but if you click on the OTHER way, then you can’t cancel it. This is absurd. Further, it takes forever – sometimes a whole hour – to install updates. No control over this is offered to the user.
What if I really have to go away, turn the computer off, catch my bus and go home? There is no option like “Stop after the current update no. 22 and leave the other 15 updates for later”... Instead, the screen prominently shows “Do not turn your computer off”. Excuse me, Microsoft...
What is this like on Linux? You are notified of new available updates. You choose when to download and install them. Most updates are applied quickly and take effect immediately. Only a few updates require a boot to take effect, and you are never really required to boot right now.
A new notebook tipically comes with at least 5 mostly useless icons in the system tray, in addition to the 3 necessary icons for sound level, network status and battery status. The 5 icons I am looking at now are:
The last two are certainly pointless and I would have them disabled. Actually as I wrote this, avast antivirus created a second icon (as if one weren’t enough to show off its work) and Windows created yet another to say it is downloading more updates... Total icons: 10.
Further, many applications we install under Windows like to add their own toolbars (unrelated to the reason you’re installing the app for) to web browsers, stealing screen space, confusing the user, who most likely never uses the toolbar... Applications add their own icons to the Start menu, to the desktop and to the Quick Launch buttons. The Start menu has its own selection of the most used apps. What a mess!
What is this like on Linux? Since applications are mostly free software – not proprietary –, and because the most important applications are part of the operating system as packaged by an organization, there is no conflict of interest leading to desktop pollution. In practice, the desktop feels simpler and better organized.
Too many applications, and even Windows itself, are constantly demanding the user’s attention, as if saying “I need maintenance”... Countless misfeatures work this way; for instance, Windows offers to clean the desktop for you, hiding icons because you rarely use them. Of course this kind of thing steals your attention from the work you are actually doing, they are annoyances.
Windows users have developed a default reaction to difficult questions that pop up: without even thinking, they click on the X to close the window with the question. Needless to say, this is a pathological reaction to a sick situation. The question could be important, just closing the window could be like hiding a problem from yourself...
The simple fact is user’s aren’t bothered quite so much in other operating systems, these just don’t need any maintenance.
What is this like on Linux? No weird questions pop up, you just work without being interrupted, save from the software update question, which can have its periodicity configured (daily or weekly). Linux should not be installed by people who don’t know what they are doing – but once installed, using it is a breeze. For my grandmother, I installed Ubuntu Linux.
Windows Vista introduced a security misfeature that occurs when you are doing some simple change to the system configuration. A window pops up asking for your confirmation, after all, someone else (or a malicious program) could be trying to execute the configuration, and Windows cannot tell if it is the user...
The effect of this is that the user experience under Windows, as of 2012, is one of clicking much more to do the same configurations, than any of the other operating systems. I wonder, how do these manage to be much more secure, yet bother the user much less?
What is this like on Linux? This problem does not exist, it is just the result of Microsoft incompetence on Windows.
Unless you really need to use software that is only available on the Windows platform – i.e. AutoCAD –, it makes no sense to pay for it. Linux comes with much more functionality and costs nothing.
For Adobe design software you have the option of using an Apple computer, which is not cheap, but does not suffer from insecurity or excess of difficult questions...
Microsoft does not deserve that you honor it with your preference, since it is known for immoral and illegal actions in the computer market, both against competitors and against consumers. I shall mention only one immoral practice against consumers which should be enough to convince you: the Starter Edition – a severely crippled operating system that prevents the user from opening more than 3 applications simultaneously, or storing more than 120 GB on their hard drive, or using more than 512 MB RAM... This is pure evil because in Brazil computers with this system preinstalled have been sold to unsuspecting customers, who then had to replace it.
After winning the browser wars, effectively driving Netscape Navigator out of the market, Microsoft didn’t work on its browser, Internet Explorer, for years and years, ignoring the cries of web developers against its hundreds of bugs. Microsoft only started improving this situation after a better browser, Mozilla Firefox, finally appeared to endanger IE.
Now Chrome is the most popular browser but IE still holds the web back to an extent, since it is still popular but lagging behind the other browsers in support for the newest web standards.
When you use Internet Explorer you help drive the statistics to its favour, which influences decisions that hold back the web. So don’t use it. This is a product that does not deserve your preference.
If you are at all interested in computing or invention or creativity, you shall now watch this talk by Bret Victor.
In June 2004 I started a blog using a full-featured CMS written in PHP. The first post was titled Nando Florestan’s site is now interactive. I was very excited...
Today I am starting a new blog ― and I am also excited because I can finally get rid of the old thing, using something much simpler: Tinkerer, a static blog generator written in Python.
There is a powerful text markup language that Python developers have traditionally used for documentation. It is called reStructuredText. Nowadays, with everybody using Sphinx, reStructuredText is even more popular. So Python developers needed a blog system that supported reStructuredText. Blogging is easier without mental context switching between markup languages.
So when famous programmer Ben Bangert mentioned Tinkerer in a chat, I immediately knew it would be eagerly adopted by Python developers. Ben has just migrated from Tumblr to Tinkerer.
For common people who want a new blog, I still recommend Tumblr though.